
1 基本参数
- 知识库名称(必填)
- 知识库图标
- 描述
- 文档语言
- 可选参数:英文(default)、中文、越南语、葡萄牙语
- 知识库权限
- 嵌入模型:
- 创建知识库前必须在
系统模型设置里面添加Embedding和LLM模型 - 在知识库文档解析分块后就无法更改嵌入模型;若想更改,就必须删除已经存在的分块
- 创建知识库前必须在
2 解析方法
解析方法和可设置参数在创建知识库时的设置属于当前知识库中所有文档的默认设置,可以根据知识库中不同类型的文档,设置不同的解析方法。
2.1 General
可设置参数
- 页面排名(float):多个知识库组合使用时,按照pageRank对相关检索加权(计算方式:检索相关性+pageRank值=最终检索值)。
- 自动关键词(int):使用
LLM为每个chunker总结N个关键词。 - 自动问题(int):使用
LLM为每个chunker总结N个问题。 - 块Token数(int):每个
chunker的最大Token数。 - 分段标识符(str):
chunker分割符,多个分隔符使用````进行包裹。 - 布局识别和OCR:
DeepDOC:应该是基于paddleOCR的模型去微调训练的,开源出来的模型是onnx格式。plain Text:纯文本。
说明
支持的文件格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML。
此方法将简单的方法应用于块文件:
- 系统将使用视觉检测模型将连续文本分割成多个片段。
- 接下来,这些连续的片段被合并成Token数不超过“Token数”的块。
示例
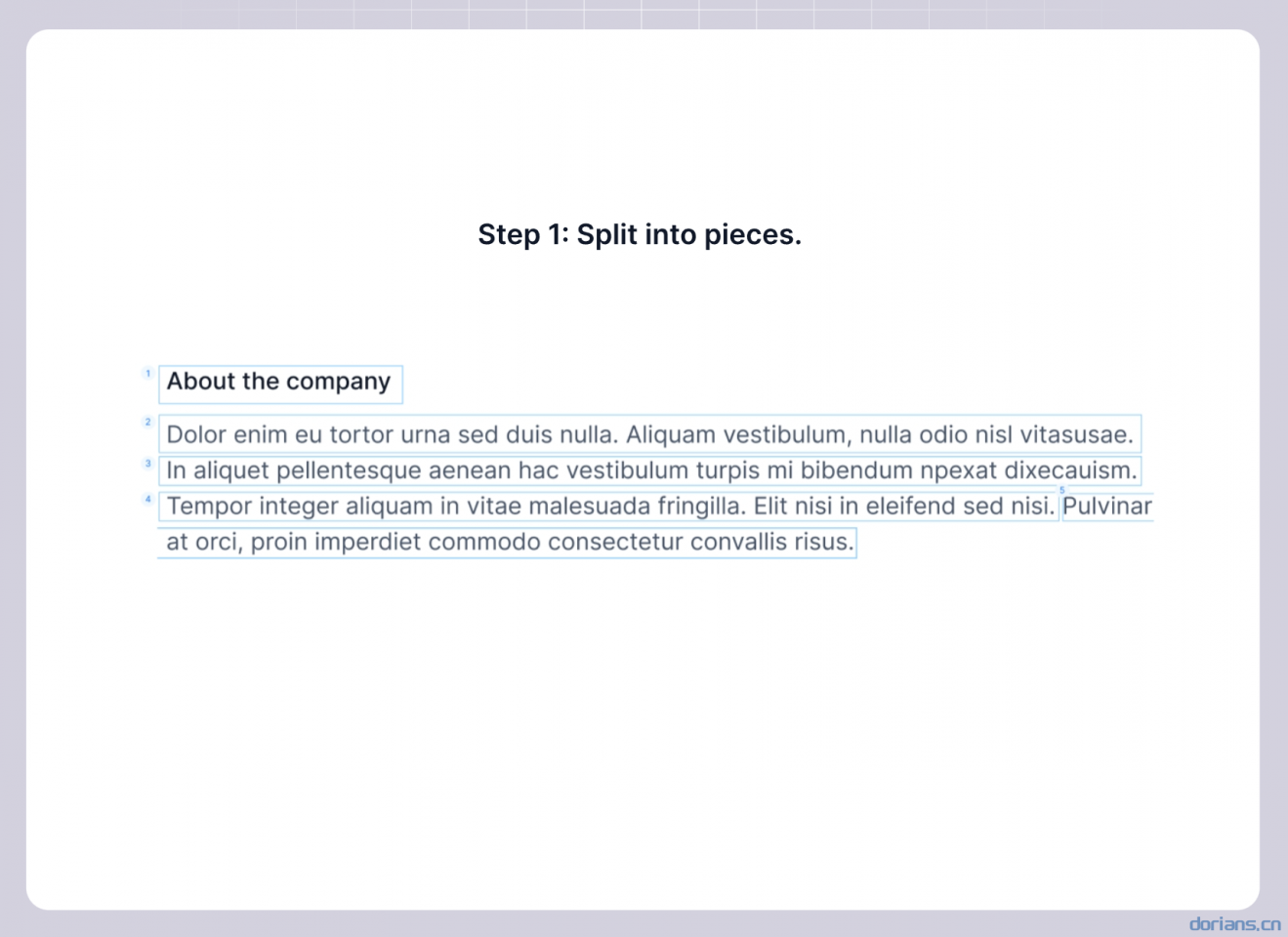
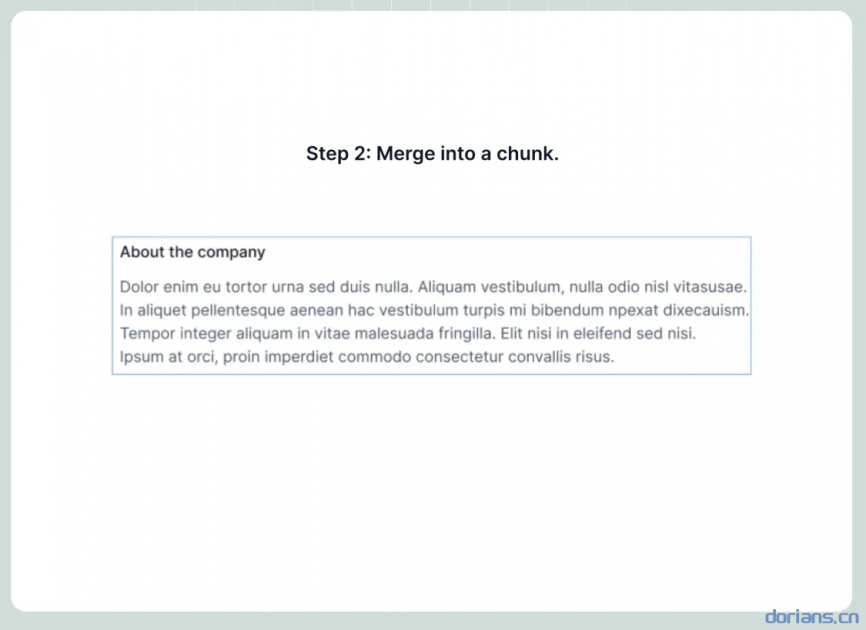
Note
使用视觉检测模型将文档先分成小块,再合并成小于指定token数的大块。
2.2 Q&A
可设置参数
- 页面排名(同上)
说明
此块方法支持 excel 和 csv/txt 文件格式。
- 如果文件是 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案, 答案列之前的问题列。多张纸是 只要列正确结构,就可以接受。
- 如果文件是 csv/txt 格式 以 UTF-8 编码且用 TAB 作分开问题和答案的定界符。
未能遵循上述规则的文本行将被忽略,并且 每个问答对将被认为是一个独特的部分。
示例

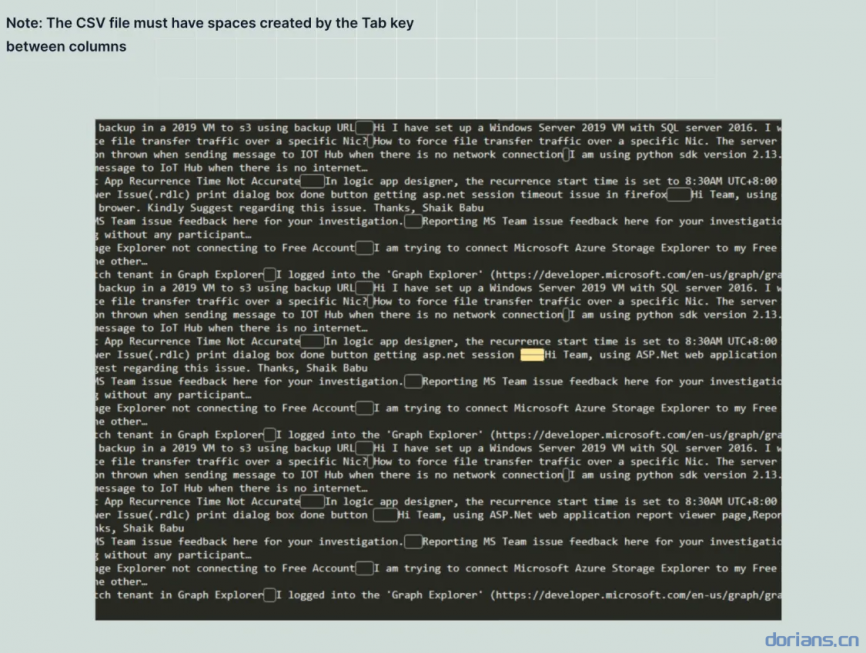
Note
针对结构化问答数据,一列问题,一列答案。
2.3 Resume
可设置参数
- 页面排名(同上)
说明
支持的文件格式为DOCX、PDF、TXT。
简历有多种格式,就像一个人的个性一样,但我们经常必须将它们组织成结构化数据,以便于搜索。
我们不是将简历分块,而是将简历解析为结构化数据。 作为HR,你可以扔掉所有的简历, 您只需与'RAGFlow'交谈即可列出所有符合资格的候选人。
示例


Note
对文档进行模块拆解,将**非标准(多种格式)**的文档拆解成逻辑清晰的模块。
2.4 Manual
可设置参数
- 页面排名(同上)
- 自动关键词(同上)
- 自动问题(同上)
说明
仅支持PDF。
我们假设手册具有分层部分结构。 我们使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
示例


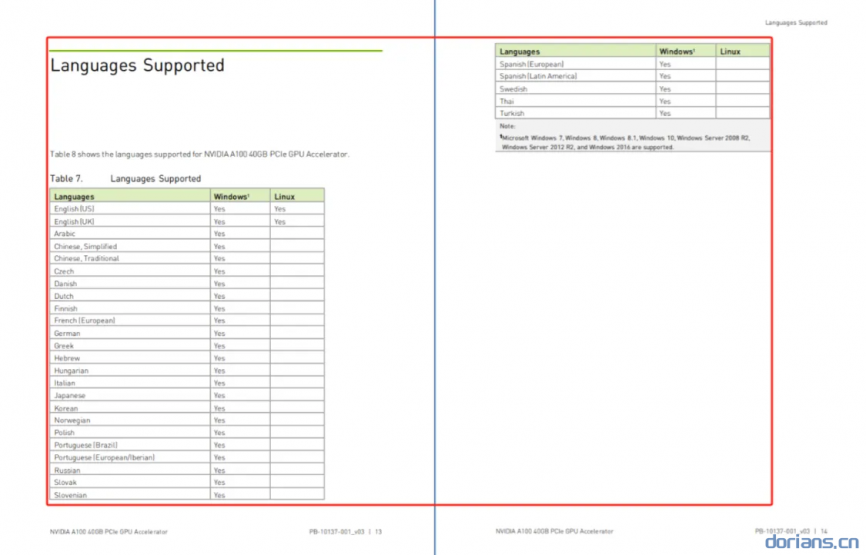
Note
对具有层级结构的文档按(最低等级)标题进行分块,会包含标题下的图片和表格导致chunker变大。
2.5 Table
可设置参数
- 页面排名(同上)
说明
支持
EXCEL和CSV/TXT格式文件。以下是一些提示:
- 对于 csv 或 txt 文件,列之间的分隔符为 TAB。
- 第一行必须是列标题。
- 列标题必须是有意义的术语,以便我们的大语言模型能够理解。 列举一些同义词时最好使用斜杠'/'来分隔,甚至更好 使用方括号枚举值,例如 'gender/sex(male,female)'.
以下是标题的一些示例:
- 供应商/供货商'TAB'颜色(黄色、红色、棕色)'TAB'性别(男、女)'TAB'尺码(M、L、XL、XXL)
- 姓名/名字'TAB'电话/手机/微信'TAB'最高学历(高中,职高,硕士,本科,博士,初中,中技,中 专,专科,专升本,MPA,MBA,EMBA)
表中的每一行都将被视为一个块。
示例
Note
针对多列结构化表格数据的检索
2.6 Paper
可设置参数
- 页面排名(同上)
- 自动关键词(同上)
- 自动问题(同上)
说明
仅支持PDF文件。
如果我们的模型运行良好,论文将按其部分进行切片,例如摘要、1.1、1.2等。
这样做的好处是LLM可以更好的概括论文中相关章节的内容, 产生更全面的答案,帮助读者更好地理解论文。 缺点是它增加了 LLM 对话的背景并增加了计算成本, 所以在对话过程中,你可以考虑减少‘topN’的设置。
示例


Note
针对论文结构的解析方法,对多栏的文档分块比较友好。
2.7 Book
可设置参数
- 页面排名(同上)
- 自动关键词(同上)
- 自动问题(同上)
说明
支持的文件格式为DOCX、PDF、TXT。
由于一本书很长,并不是所有部分都有用,如果是 PDF, 请为每本书设置页面范围,以消除负面影响并节省分析计算时间。
Note
针对大文档的解析方法,可以选择文档的解析访问,减少响应时间。
2.8 Laws
可设置参数
- 页面排名(同上)
- 自动关键词(同上)
- 自动问题(同上)
说明
支持的文件格式为DOCX、PDF、TXT。
法律文件有非常严格的书写格式。 我们使用文本特征来检测分割点。
chunk的粒度与'ARTICLE'一致,所有上层文本都会包含在chunk中。
示例


Note
利用文本特征进行检测分割,每个chunker的粒度和文档的板块粒度保持一致,保留自然逻辑单元。好处是避免重要内容被截断,缺点是如果存在较大的板块,会导致chunker太大。
3 召回增强RAPTOR策略
基于检索增强的RAPTOR策略(Recursive Abstractive Processing for Tree Organized Retrieval)通过构建层次化语义树提升长文档检索能力,结合动态聚类与多级总结优化上下文理解。
3.1 RAPTOR策略的原理
- 递归分块:将长文档以递归分块策略分成短块,优先保证句子完整性。
- 嵌入生成:将
chuner使用Embedding模型生成chunker嵌入(保证维数)。 - 降维:将
chunker降到指定N维空间 - 语义聚类:使用高斯混合模型(GMM)对
chunker进行软聚类,每个chunker可以属于多个主题组 - 层级总结:叶子节点为原始文本块,中间每一层节点为子结点的总结摘要(利用
LLM生成),根节点为整个文档的摘要。 - 检索:将问题编码为向量,在平铺的树结构中检索
topK相关节点。
3.2 RAPTOR的优点
- 提升复杂问答性能:多个中间节点的摘要信息能有效捕捉段落关联
- 提升检索性能:平铺的树结构检索比传统树遍历算法减少响应时间,同时能保持召回精度。
4 提取知识图谱
4.1 提取方法
GraphRAG
- 通过构建结构化知识图谱整合实体关系,支持多跳推理。其索引流程需对全量文档进行实体提取、关系链接和图谱构建,适合处理复杂语义关联问题(如企业级知识库问答)
- 优势:答案的全面性和推理能力突出,例如能关联电动汽车普及对电网、城市规划的多级影响链。
- 局限:图谱构建成本高(依赖LLM多次调用),动态更新需全量重建(新增同规模数据时成本达千万级token)。
LightRAG
- 采用「图结构+向量索引」的双层设计:底层保留文本向量索引,高层通过轻量图谱建立语义关联,支持增量更新(仅处理新增实体关系)。
- 创新点:引入去重机制(D(.)模块)优化图谱规模,通过联合操作无缝合并新旧知识节点,避免重复构建。
- 效率提升:相比GraphRAG,索引构建时间减少40%,API调用量降低60%。
GrphRAG与LightRAG对比
| 指标 | GraphRAG | LightRAG |
|---|---|---|
| 检索精度 | 复杂问题综合得分高(+15%) | 简单问题准确率提升20%,复杂问题持平 **** |
| 响应速度 | 平均延迟≥800ms(受图谱遍历复杂度影响) | 平均延迟≤300ms(双层并行检索优化) |
| 更新成本 | 全量重建,百万级token消耗 | 增量更新,万级token消耗 |
其他设置
- 实体归一化(实体对齐):合并相同含义的实体
- 社区报告:先利用社群算法进行聚类生成子图,再利用
LLM对子图的总结摘要(类似RAPTOR策略中的层级摘要)
